One of the most common issues encountered with Azure Synapse Dedicated SQL Pools is the confusion of table creation. The confusion stems from separating how a table is stored from where it is stored. I have already talked a little bit about this in previous posts (regarding distribution and indexing) but I want to dedicate this post to adding some clarity on the topic.
First, let’s take a look at the table creation statement in very simple generic form:
CREATE TABLE [TableName]
([col1] datatype, [col2] datatype, …)
WITH (DISTRIBUTION=[distribution type], [index type])
The two key components for Synapse Dedicated SQL Pools are within the WITH clause: 1.) Distribution and 2.) Index. Every table has these two properties even if they are not declared explicitly. Synapse will default the distribution type to Round Robin and will default the index to a Clustered Columnstore Index (CCI) if not explicitly defined.
I typically describe these two properties as follows.
- A distribution type is where data is stored physically. When data is inserted, is it stored on the next distribution available (Round Robin) or is it stored on a specific distribution determined by a hash key and algorithm (Hash distributed). Replicated tables are a variation of round robin tables with a caching layer over the top.
- An index type determines how data is stored. First, is it stored in rowstore format in pages (clustered Index/heap) or is it stored in columnar compressed format (CCI)? Secondarily, is there any ordering to the data? The ordering will determine if the table is a (CCI vs Ordered CCI and Clustered Index vs Heap).
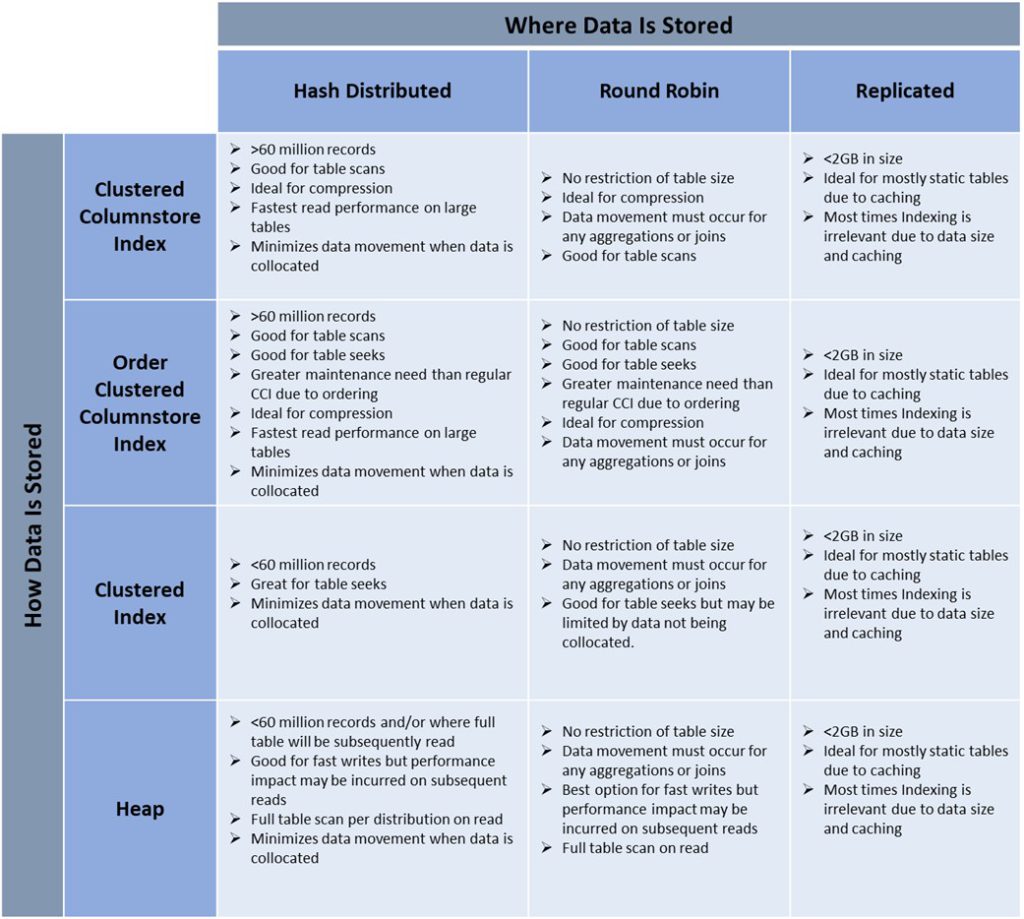
To simplify and illustrate the above concepts, I typically walk through a chart like the one below. This forces you to think about the impact of choosing specific distribution and indexing types. Note that this chart is academic and may not apply to edge cases or unique scenarios. It is however a good place to start when you are in the beginning stages of creating your table schema and understanding the performance impacts of those choices. Use the below matrix as a starting point. Expand on the characteristics and best practices listed below that the different index and distribution types bring when creating tables in your own environment.
![]()