So why are computed columns such a big performance consideration in Synapse Dedicated SQL Pools? There are two main reasons:
- CPU pressure
- Statistics
Many times, computed columns are just a variation of the data that was originally stored in the source system. Instead of transforming the data as part of an ELT (Extract, Load, and Transform) process, a decision was made (or not made) to not materialize nor persist calculated data that is needed for reporting purposes. Business logic is applied repeatedly every time a dataset is queried which opposes principles of reuse. This is also contrary to the basic principles of data warehousing for the purpose of abiding by the principle of only storing data once. Data warehousing in its very nature is denormalizing data for reporting performance and in doing so requires multiple copies. If you don’t push the transformation logic upstream and copy the data in a denormalized format you are not effectively using your data warehouse platform. A colleague of mine, Matthew Roche states it this way: “Data should be transformed as far upstream as possible, and as far downstream as necessary.” Roche’s Maxim of Data Transformation – BI Polar (ssbipolar.com)
CPU pressure is not a unique symptom to Synapse Dedicated SQL Pools but is a common symptom for all SQL platforms. Save the CPU intensive operations for a one-time load operation instead of repeatedly putting CPU pressure on the environment.
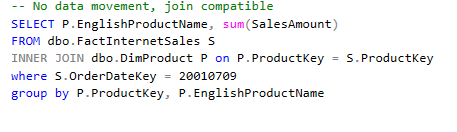
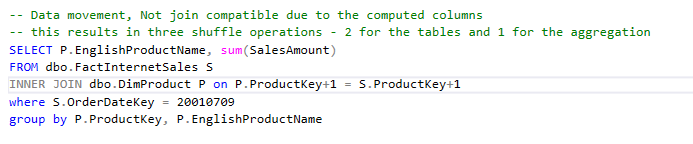
Statistics are the second and the most important performance consideration in context of Synapse. I have covered this in the very first post in this series and will expand on it here due to its importance. Computed columns leveraged as part of a join clause or as part of a select statement in a nested view will not have statistics for the query optimizer to put together an effective query plan. When the query optimizer does not have statistics, it can only do 1 of two things: 1.) assume that there are 1000 records in the dataset (that is the default value the optimizer will use if there are no stats on a table) or 2.) use the table statistic that tells how many records are in the whole table. This can result in incorrect data movements (moving the larger of the two datasets) to allow for join compatibility and cannot be overcome by redistributing tables. The following is an example of two queries using the AdventureWorks database that are equivalent but have drastically different dsql plans just by adding a calculation on the join fields. This creates much more work for the query engine and can impact the performance of your entire environment. While this is a simple example, try to imagine how your users might do something similar using business data. If you need a quick refresher on query plans check out my previous post here: Synapse Dedicated SQL Pool Execution Plans – Daniel Crawford’s Data Blog


![]()